Similarity check in scientific texts
Via the Crossref Similarity site, it is possible to access iThenticate – a text similarity check service which helps to examine the authenticity of scientific texts.
iThenticate compares manuscripts with its own constantly expanding database containing a large number (tens of millions) of documents from scientific conferences, journals and books. The tool runs a search on the internet as well as in several other content delivery databases.
Uploading
This service can currently be used with the help of a librarian. Checks can be requested by email at szolg@uni-corvinus.hu.
Besides providing mandatory data (i.e. first name, surname, title of document), the document should fulfil the following requirements:
- size smaller than 100MB;
- up to 800 pages;
- at least 20 words;
- word-only files cannot exceed 2MB;
- maximum size of compressed files 200MB, or 1000 files.
Currently, the following file formats can be uploaded:
MS Word (doc, docx), Text (txt), PostScript, PDF, HTML, Excel, PowerPoint, Word Perfect WPD, OpenOffice ODT, RTF, Hangul HWP
As soon as the check is complete, the programme creates a similarity index, and the details can be viewed by clicking the result. In most cases, the similarity score is used to measure the extent of similarity between a manuscript and previously published texts.
In iThenticate, after clicking the similarity index, the following window opens:
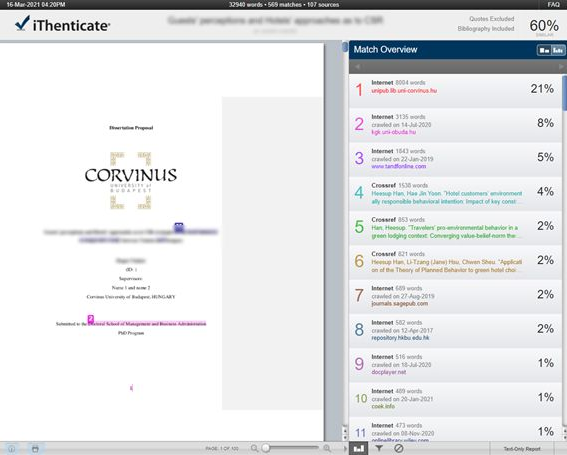
The general similarity index of the full manuscript can be found in the top right corner. The match overview will show the user which database sources should be examined due to a possible text similarity. It will also show the similarity index of the specified sources and the number of similar words.
Besides the similarity index, some exclusions selected by the user are also displayed (e.g. whether quotes or the bibiography have been filtered).
The report highlights specific sources in the main text using colours and numbers (on the left), so the user can easily see the problematic areas within the text.
What does the iThenticate similarity report contain?
- The manuscript with highlighted parts. The highlighted parts mark the similarity with already published material.
- The listing of specific sources. These sources are ranked according to percentage which shows the extent of their similarity to the manuscript.
- The similarity index. The similarity index is a complete similarity check between the manuscript and the published text in terms of percentage. In order to reduce the risk of false positive data, it is advised to only apply this to the main text of the manuscript, not to the list of literature or the quotes.
In addition, short texts marked in a similar way as published sources can be excluded (up to ten words).
The pdf report can be downloaded from the page, the similarity overview can usually be found at the end of the highlighted item. Pdf files allow for fewer dynamic functions, but at the bottom some database sources can be accessed by clicking, so we can get to the required material. As an alternative solution, we can also check which numbered sources refer to which sentences by colour-coding the main text.
What extent of similarity is allowed?
We don’t have a standard percentage limit of similarity. Sometimes a higher similarity score is less problematic than an article with a lower similarity score that contains a paragraph that has been directly copied from another source.
How can we use the iThenticate similarity report?
The following questions should be especially considered:
- Chunks of text with a lot of similarity, for example a full sentence or a line within the same paragraph

- Repeated similarity with the same source(s)
The following aspects are less worrying:
- A similar text that consists of standard phrases generally used in its scientific field, instead of referring to one or a few specific sources;
- A similar text that consist of descriptions of previously published methods.